Difference between revisions of "Ruby"
m (→High level components of Ruby) |
m (→Ruby) |
||
| Line 8: | Line 8: | ||
# Rapid prototyping -- a high-level specification language, SLICC, is used to specify functionality of various controllers. | # Rapid prototyping -- a high-level specification language, SLICC, is used to specify functionality of various controllers. | ||
| − | [[Image:ruby_overview.jpg]] | + | Image upload in progress |
| + | [[Image:ruby_overview.jpg]] | ||
The main components of Ruby are as follows: | The main components of Ruby are as follows: | ||
Revision as of 06:15, 16 March 2011
Contents
- 1 Ruby
- 1.1 High level components of Ruby
- 1.2 Implementation of Ruby
- 1.2.1 Directory Structure
- 1.2.2 SLICC
- 1.2.3 Protocols
- 1.2.4 Protocol Independent Memory components
- 1.2.5 Interconnection Network
- 1.2.6 Life of a memory request in Ruby
Ruby
High level components of Ruby
Ruby implements a detailed simulation model for the memory subsystem. It models inclusive/exclusive cache hierarchies with various replacement policies, coherence protocol implementations, interconnection networks, DMA and memory controllers, various sequencers that initiate memory requests and handle responses. The models are modular, flexible and highly configurable. Three key aspects of these models are:
- Separation of concerns -- for example, the coherence protocol specifications are separate from the replacement policies and cache index mapping, the network topology is specified separately from the implementation.
- Rich configurability -- almost any aspect affecting the memory hierarchy functionality and timing can be controlled.
- Rapid prototyping -- a high-level specification language, SLICC, is used to specify functionality of various controllers.
Image upload in progress
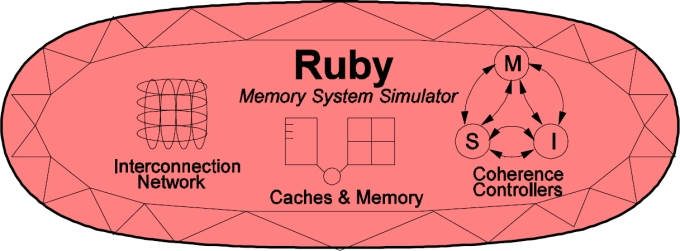

The main components of Ruby are as follows:
SLICC + Coherence protocols:
Need to say what is SLICC and whats its purpose. Talk about high level strcture of a typical coherence protocol file, that SLICC uses to generate code. A simple example structure from protocol like MI_example can help here.
Nilay will do it
Protocol independent memory components
- Cache Memory
- Replacement Policies
- Memory Controller
Arka will do it
Interconnection Network
The interconnection network connects the various components of the memory hierarchy (cache, memory, dma controllers) together. There are 3 key parts to this:
- Topology specification: These are specified with python files that describe the topology (mesh/crossbar/ etc.), link latencies and link bandwidth. The network topology is thus configurable.
- Cycle-accurate network model: Garnet is a cycle accurate, pipelined, network model that builds and simulates the specified topology. It simulates the router pipeline and movement of flits across the network subject to the routing algorithm, latency and bandwidth constraints.
- Network Power model: The Orion power model is used to keep track of router and link activity in the network. It calculates both router static power and link and router dynamic power as flits move through the network.
More details about the network model implementation are described here
Implementation of Ruby
Directory Structure
- src/mem/
- protocols: SLICC specification for coherence protocols
- slicc: implementation for SLICC parser and code generator
- ruby
- buffers: implementation for message buffers that are used for exchanging information between the cache, directory, memory controllers and the interconnect
- common: frequently used data structures, e.g. Address (with bit-manipulation methods), histogram, data block, basic types (int32, uint64, etc.)
- eventqueue: Ruby’s event queue mechanism for scheduling events
- filters: various Bloom filters
- network: Interconnect implementation, sample topology specification, network power calculations
- profiler: Profiling for cache events, memory controller events
- recorder: Cache warmup and access trace recording
- slicc_interface: Message data structure, various mappings (e.g. address to directory node), utility functions (e.g. conversion between address & int, convert address to cache line address)
- system: Protocol independent memory components – CacheMemory, DirectoryMemory, Sequencer, RubyPort
SLICC
Explain functionality/ capability of SLICC Talk about AST, Symbols, Parser and code generation in some details but NO need to cover every file and/or functions. Few examples should suffice.
Nilay will do it
Protocols
Need to talk about each protocol being shipped. Need to talk about protocol specific configuration parameters. NO need to explain every action or every state/events, but need to give overall idea and how it works and assumptions (if any).
Common Notations and Data Structures
Coherence Messages
These are described in the <protocol-name>-msg.sm file for each protocol.
| Message | Description |
|---|---|
| ACK/NACK | positive/negative acknowledgement for requests that wait for the direction of resolution before deciding on the next action. Examples are writeback requests, exclusive requests. |
| GETS | request for shared permissions (e.g. load, IFetch). |
| GETX | request for exclusive access. |
| INV | invalidation request. This can be triggered by the coherence protocol itself, or by the next cache level/directory to enforce inclusion or to trigger a writeback for a DMA access so that the latest copy of data is obtained. |
| PUTX | request for writeback of cache block. Some protocols (e.g. MOESI_CMP_directory) may use this only for writeback requests of exclusive data. |
| PUTS | request for writeback of cache block in shared state. |
| PUTO | request for writeback of cache block in owned state. |
| PUTO_Sharers | request for writeback of cache block in owned state but other sharers of the block exist. |
| UNBLOCK | message to unblock next cache level/directory for blocking protocols. |
AccessPermissions
These are associated with each cache block and determine what operations are permitted on that block. It is closely correlated with coherence protocol states.
| Permissions | Description |
|---|---|
| Invalid | The cache block is invalid. The block must first be obtained (from elsewhere in the memory hierarchy) before loads/stores can be performed. No action on invalidates (except maybe sending an ACK). No action on replacements. The associated coherence protocol states are I or NP and are stable states in every protocol. |
| Busy | TODO |
| Read_Only | Only operations permitted are loads, writebacks, invalidates. Stores cannot be performed before transitioning to some other state. |
| Read_Write | Loads, stores, writebacks, invalidations are allowed. Usually indicates that the block is dirty. |
Data Structures
- Message Buffers:TODO
- TBE Table: TODO
- Timer Table: This maintains a map of address-based timers. For each target address, a timeout value can be associated and added to the Timer table. This data structure is used, for example, by the L1 cache controller implementation of the MOESI_CMP_directory protocol to trigger separate timeouts for cache blocks. Internally, the Timer Table uses the event queue to schedule the timeouts. The TimerTable supports a polling-based interface, isReady() to check if a timeout has occurred. Timeouts on addresses can be set using the set() method and removed using the unset() method.
- Related Files:
- src/mem/ruby/system/TimerTable.hh: Declares the TimerTable class
- src/mem/ruby/system/TimerTable.cc: Implementation of the methods of the TimerTable class, that deals with setting addresses & timeouts, scheduling events using the event queue.
- Related Files:
MI example
This is a simple cache coherence protocol that is used to illustrate protocol specification using SLICC.
Related Files
- src/mem/protocols
- MI_example-cache.sm: cache controller specification
- MI_example-dir.sm: directory controller specification
- MI_example-dma.sm: dma controller specification
- MI_example-msg.sm: message type specification
- MI_example.slicc: container file
Cache Hierarchy
This protocol assumes a 1-level cache hierarchy. The cache is private to each node. The caches are kept coherent by a directory controller. Since the hierarchy is only 1-level, there is no inclusion/exclusion requirement. This protocol does not differentiate between loads and stores.
Stable States and Invariants
| States | Invariants |
|---|---|
| M | The cache block has been accessed (read/written) by this node. No other node holds a copy of the cache block |
| I | The cache block at this node is invalid |
Cache controller
- Requests, Responses, Triggers:
- Load, Instruction fetch, Store from the core
- Replacement from self
- Data from the directory controller
- Forwarded request (intervention) from the directory controller
- Writeback acknowledgement from the directory controller
- Invalidations from directory controller (on dma activity)
- Main Operation:
- On a load/Instruction fetch/Store request from the core:
- it checks whether the corresponding block is present in the M state. If so, it returns a hit
- otherwise, if in I state, it initiates a GETX request from the directory controller
- On a load/Instruction fetch/Store request from the core:
- On a replacement trigger from self:
- it evicts the block, issues a writeback request to the directory controller
- it waits for acknowledgement from the directory controller (to prevent races)
- On a replacement trigger from self:
- On a forwarded request from the directory controller:
- This means that the block was in M state at this node when the request was generated by some other node
- It sends the block directly to the requesting node (cache-to-cache transfer)
- It evicts the block from this node
- On a forwarded request from the directory controller:
- Invalidations are similar to replacements
Directory controller
- Requests, Responses, Triggers:
- GETX from the cores, Forwarded GETX to the cores
- Data from memory, Data to the cores
- Writeback requests from the cores, Writeback acknowledgements to the cores
- DMA read, write requests from the DMA controllers
- Main Operation:
- The directory maintains track of which core has a block in the M state. It designates this core as owner of the block.
- On a GETX request from a core:
- If the block is not present, a memory fetch request is initiated
- If the block is already present, then it means the request is generated from some other core
- In this case, a forwarded request is sent to the original owner
- Ownership of the block is transferred to the requestor
- On a writeback request from a core:
- If the core is owner, the data is written to memory and acknowledgement is sent back to the core
- If the core is not owner, a NACK is sent back
- This can happen in a race condition
- The core evicted the block while a forwarded request some other core was on the way and the directory has already changed ownership for the core
- The evicting core holds the data till the forwarded request arrives
- On DMA accesses (read/write)
- Invalidation is sent to the owner node (if any). Otherwise data is fetched from memory.
- This ensures that the most recent data is available.
Other features
- MI protocols don't support LL/SC semantics. A load from a remote core will invalidate the cache block.
- This protocol has no timeout mechanisms.
MOESI_hammer
Somayeh will do it
MOESI_CMP_token
Shoaib will do it
MOESI_CMP_directory
In contrast with the MESI protocol, the MOESI protocol introduces an additional Owned state. This enables sharing of a block after modification without needing to write it back to memory first. However, in that case, only 1 node is the owner while the others are sharers. The owner node has the responsibility to write the block back to memory on eviction. Sharers may evict the block without writeback. An overview of the protocol can be found here.
Related Files
- src/mem/protocols
- MOESI_CMP_directory-L1cache.sm: L1 cache controller specification
- MOESI_CMP_directory-L2cache.sm: L2 cache controller specification
- MOESI_CMP_directory-dir.sm: directory controller specification
- MOESI_CMP_directory-dma.sm: dma controller specification
- MOESI_CMP_directory-msg.sm: message type specification
- MOESI_CMP_directory.slicc: container file
Cache Hierarchy
L1 Cache
- Stable States and Invariants
| States | Invariants |
|---|---|
| M | TODO |
| O | TODO |
| S | TODO |
| I | TODO |
| M_W | TODO |
| MM | TODO |
| MM_W | TODO |
- Controller
L2 Cache
- Stable States and Invariants
| States | Invariants |
|---|---|
| NP/I | TODO |
| ILS | TODO |
| ILX | TODO |
| ILO | TODO |
| ILOX | TODO |
| ILOS | TODO |
| ILOSX | TODO |
| S | TODO |
| O | TODO |
| OLS | TODO |
| OLSX | TODO |
| SLS | TODO |
| M | TODO |
- Controller
Directory
- Stable States and Invariants
| States | Invariants |
|---|---|
| M | TODO |
| O | TODO |
| S | TODO |
| I | TODO |
- Controller
Other features
- Timeouts:
Rathijit will do it
MESI_CMP_directory
Arka will do it
Protocol Independent Memory components
System
Arka will do it
Sequencer
Arka will do it
CacheMemory and Cache Replacement Polices
Under Construction. Please do not Edit --- Arka
This module can model any Set-associative Cache structure with a given associativity. Each instantiation of the following module models a single bank of a cache. Thus different types of caches in system (e.g. L1 Instruction, L1 Data , L2 etc) and every banks of a cache needs to have separate instantiation of this module. This module can also model Fully associative cache when the associativity is set to 1. In Ruby memory system, this module is primarily expected to be accessed by the SLICC generated codes of the given Coherence protocol being modeled.
Basic Operation
This module models the set-associative structure as a two dimensional (2D) array. Each row of the 2D array represents a set of in the set-associative cache structure, while columns represents ways. The number of columns is equal to the given associativity (parameter), while the number of rows is decided depending on the desired size of the structure (parameter), associativity (parameter) and the size of the cache line (parameter). This module exposes six important functionalities which Coherence Protocols uses to manage the caches.
- It allows to query if a given cache line address is present in the set-associative structure being modeled through a function named isTagPresent. This function returns true, iff the given cache line address is present in it.
- It allows a lookup operation which returns the cache entry for a given cache line address (if present), through a function named lookup. It returns NULL if the blocks with given address is not present in the set-associative cache structure.
- It allows to allocate a new cache entry in the set-associative structure through a function named allocate.
- It allows to deallocate a cache entry of a given cache line address through a function named deallocate.
- It can be queried to find out whether to allocate an entry with given cache line address would require replacement of another entry in the designated set (derived from the cache line address) or not. This functionality is provided through cacheAvail function, which for a given cache line address, returns True, if NO replacement of another entry the same set as the given address is required to make space for a new entry with the given address.
- The function cacheProbe is used to find out cache line address of a victim line, in case placing a new entry would require victimizing another cache blocks in the same set. This function returns the cache line address of the victim line given the address of the address of the new cache line that would have to be allocated.
Parameters
There are four important parameters for this class.
- size is the parameter that provides the size of the set-associative structure being modeled in units of bytes.
- assoc specifies the set-associativity of the structure.
- replacement_policy is the name of the replacement policy that would be used to select victim cache line when there is conflict in a given set. Currently, only two possible choices are available (PSEUDO_LRU and LRU).
- Finally, start_index_bit parameter specifies the bit position in the address from where indexing into the cache should start. This is a tricky parameter and if not set properly would end up using only portion of the cache capacity. Thus how this value should be specified is explained through couple of examples. Let us assume the cache line size if 64 bytes and a single core machine with a L1 cache with only one bank and a L2 cache with 4 banks. For the CacheMemory module that would model the L1 cache should have start_index_bit set to log2(64) = 6 (this is the default value assuming 64 bytes cache line). This is required as addresses passed around in the Ruby is full address (i.e. equal to the number of bits required to access any address in the physical address range) and as the caches would be accessed in granularity of cache line size (here 64 bytes), the lower order 6 bits in the address would be essentially 0. So we should discard last 6 bits of the given address while calculating which set (index) in the set associative structure the given address should go to. Now let's look into a more complicated case of L2 cache, which has 4 banks. As mentioned previously, this modules models a single bank of a set-associative cache. Thus there will be four instantiation of the CacheMemory class to model the whole L2 cache. Assuming which cache bank a request goes to is statically decided by the low oder log2(4) = 2 bits of the cache line address, the value of the bits in the address at the position 6 and 7 would be same for all accesses coming to a given bank (i.e. a instance of CacheMemory here). Thus indexing within the set associative structure (CacheMemory instance) modeling a given bank should use address bits 8 and higher for finding which set a cache block should go to. Thus start_index_bit parameter should be set to 8 for the banks of L2 in this example. If erroneously if this is set 6, only a fourth of desired L2 capacity would be utilized !!!
More detailed description of operation
As mentioned previously, the set-associative structure is modeled as a 2D array in the CacheMemory class. The variable m_cache is this all important 2D array containing the set-associative structure. Each element of this 2D array is derived from type AbstarctCacheEntry class. Beside the minimal required functionality and contents of each cache entry, it can be extended inside the Coherence protocol files. This allows CacheMemory to be generic enough to hold any type of cache entry as desired by a given Coherence protocol as long as it derives from AbstractCacheEntry interface.
Related files
- src/mem/ruby/system
- CacheMemory.cc: contains CacheMemory class which models a cache bank
- CacheMemory.hh: Interface for the CacheMemory class
- Cache.py: Python configuration file for CacheMemory class
- AbstractReplacementPolicy.hh: Generic interface for Replacement policies for the Cache
- LRUPolicy.hh: contains LRU replacement policy
- PseudoLRUPolicy.hh: contains Pseudo-LRU replacement policy
- src/mem/ruby/slicc_interface
- AbstarctCacheEntry.hh: contains the interface of Cache Entry
DMASequencer
This module implements handling for DMA transfers. It is derived from the RubyPort class. There can be a number of DMA controllers that interface with the DMASequencer. The DMA sequencer has a protocol-independent interface and implementation. The DMA controllers are described with SLICC and are protocol-specific.
Note:
- There can be only 1 DMASequencer in the system.
- At any time there can be only 1 request active in the DMASequencer.
- Only ordinary load and store requests are handled. No other request types such as Ifetch, RMW, LL/SC are handled
Related Files
- src/mem/ruby/system
- DMASequencer.hh: Declares the DMASequencer class and structure of a DMARequest
- DMASequencer.cc: Implements the methods of the DMASequencer class, such as request issue and callbacks.
Configuration Parameters
Currently there are no special configuration parameters for the DMASequencer.
Basic Operation
A request for data transfer is split up into multiple requests each transferring cache-block-size chunks of data. A request is active as long as all the smaller transfers are not completed. During this time, the DMASequencer is in a busy state and cannot accepts any new transfer requests.
DMA requests are made through the makeRequest method. If the sequencer is not busy and the request is of the correct type (LD/ST), it is accepted. A sequence of requests for smaller data chunks is then issued. The issueNext method issues each of the smaller requests. A data/acknowledgment callback signals completion of the last transfer and triggers the next call to issueNext as long as all of the original data transfer is not complete. There is no separate event scheduler within the DMASequencer.
Memory Controller
Most (but not all) of the writeup in this section is taken verbatim from documentation in the gem5 source files and rubyconfig.defaults file of GEMS.
This module simulates a basic DDR-style memory controller. It models a single channel, connected to any number of DIMMs with any number of ranks of DRAMs each. If you want multiple address/data channels, you need to instantiate multiple copies of this module.
Note:
- The product of the memory bus cycle multiplier, memory controller latency, and clock cycle time(=1/processor frequency) gives a first-order approximation of the latency of memory requests in time. The Memory Controller module refines this further by considering bank & bus contention, queueing effects of finite queues, and refreshes.
- Data sheet values for some components of the memory latency are specified in time (nanoseconds), whereas the Memory Controller module expects all delay configuration parameters in cycles. The parameters should be set appropriately taking into account the processor and bus frequencies.
- The current implementation does not consider pin-bandwidth contention. Infinite bandwidth is assumed.
- Only closed bank policy is currently implemented; that is, each bank is automatically closed after a single read or write.
- This is the only controller that is NOT specified in SLICC, but in C++.
Related Files
- src/mem/ruby/system
- MemoryControl.hh: This file declares the Memory Controller class.
- MemoryControl.cc: This file implements all the operations of the memory controller. This includes processing of input packets, address decoding and bank selection, request scheduling and contention handling, handling refresh, returning completed requests to the directory controller.
- MemoryControl.py: Configuration parameters
Configuration Parameters
- dimms_per_channel: Currently the only thing that matters is the number of ranks per channel, i.e. the product of this parameter and ranks_per_dimm. But if and when this is expanded to do FB-DIMMs, the distinction between the two will matter.
- Address Mapping: This is controlled by configuration parameters banks_per_rank, bank_bit_0, ranks_per_dimm, rank_bit_0, dimms_per_channel, dimm_bit_0. You could choose to have the bank bits, rank bits, and DIMM bits in any order. For the default values, we assume this format for addresses:
- Offset within line: [5:0]
- Memory controller #: [7:6]
- Bank: [10:8]
- Rank: [11]
- DIMM: [12]
- Row addr / Col addr: [top:13]
If you get these bits wrong, then some banks won't see any requests; you need to check for this in the .stats output.
- mem_bus_cycle_multiplier: Basic cycle time of the memory controller. This defines the period which is used as the memory channel clock period, the address bus bit time, and the memory controller cycle time. Assuming a 200 MHz memory channel (DDR-400, which has 400 bits/sec data), and a 2 GHz processor clock, mem_bus_cycle_multiplier=10.
- mem_ctl_latency: Latency to returning read request or writeback acknowledgement. Measured in memory address cycles. This equals tRCD + CL + AL + (four bit times) + (round trip on channel) + (memory control internal delays). It's going to be an approximation, so pick what you like. Note: The fact that latency is a constant, and does not depend on two low-order address bits, implies that our memory controller either: (a) tells the DRAM to read the critical word first, and sends the critical word first back to the CPU, or (b) waits until it has seen all four bit times on the data wires before sending anything back. Either is plausible. If (a), remove the "four bit times" term from the calculation above.
- rank_rank_delay: This is how many memory address cycles to delay between reads to different ranks of DRAMs to allow for clock skew.
- read_write_delay: This is how many memory address cycles to delay between a read and a write. This is based on two things: (1) the data bus is used one cycle earlier in the operation; (2) a round-trip wire delay from the controller to the DIMM that did the reading. Usually this is set to 2.
- basic_bus_busy_time: Basic address and data bus occupancy. If you are assuming a 16-byte-wide data bus (pairs of DIMMs side-by-side), then the data bus occupancy matches the address bus occupancy at 2 cycles. But if the channel is only 8 bytes wide, you need to increase this bus occupancy time to 4 cycles.
- mem_random_arbitrate: By default, the memory controller uses round-robin to arbitrate between ready bank queues for use of the address bus. If you wish to add randomness to the system, set this parameter to one instead, and it will restart the round-robin pointer at a random bank number each cycle. If you want additional nondeterminism, set the parameter to some integer n >= 2, and it will in addition add a n% chance each cycle that a ready bank will be delayed an additional cycle. Note that if you are in mem_fixed_delay mode (see below), mem_random_arbitrate=1 will have no effect, but mem_random_arbitrate=2 or more will.
- mem_fixed_delay: If this is nonzero, it will disable the memory controller and instead give every request a fixed latency. The nonzero value specified here is measured in memory cycles and is just added to MEM_CTL_LATENCY. It will also show up in the stats file as a contributor to memory delays stalled at head of bank queue.
- tFAW: This is an obscure DRAM parameter that says that no more than four activate requests can happen within a window of a certain size. For most configurations this does not come into play, or has very little effect, but it could be used to throttle the power consumption of the DRAM. In this implementation (unlike in a DRAM data sheet) TFAW is measured in memory bus cycles; i.e. if TFAW = 16 then no more than four activates may happen within any 16 cycle window. Refreshes are included in the activates.
- refresh_period: This is the number of memory cycles between refresh of row x in bank n and refresh of row x+1 in bank n. For DDR-400, this is typically 7.8 usec for commercial systems; after 8192 such refreshes, this will have refreshed the whole chip in 64 msec. If we have a 5 nsec memory clock, 7800 / 5 = 1560 cycles. The memory controller will divide this by the total number of banks, and kick off a refresh to somebody every time that amount is counted down to zero. (There will be some rounding error there, but it should have minimal effect.)
- Typical Settings for configuration parameters: The default values are for DDR-400 assuming a 2GHz processor clock. If instead of DDR-400, you wanted DDR-800, the channel gets faster but the basic operation of the DRAM core is unchanged. Busy times appear to double just because they are measured in smaller clock cycles. The performance advantage comes because the bus busy times don't actually quite double. You would use something like these values:
- mem_bus_cycle_multiplier: 5
- bank_busy_time: 22
- rank_rank_delay: 2
- read_write_delay: 3
- basic_bus_busy_time: 3
- mem_ctl_latency: 20
- refresh_period: 3120
Basic Operation
- Data Structures
Requests are enqueued into a single input queue. Responses are dequeued from a single response queue. There is a single bank queue for each DRAM bank (the total number of banks is the number of DIMMs per channel x number of ranks per DIMM x number of banks per rank). Each bank also has a busy counter. tFAW shift registers are maintained per rank.
- Scheduling and Bank Contention
The wakeup function, and in turn, the executeCycle function is tiggered once every memory clock cycle.
Each memory request is placed in a queue associated with a specific memory bank. This queue is of finite size; if the queue is full the request will back up in an (infinite) common queue and will effectively throttle the whole system. This sort of behavior is intended to be closer to real system behavior than if we had an infinite queue on each bank. If you want the latter, just make the bank queues unreasonably large.
The head item on a bank queue is issued when all of the following are true:
- The bank is available
- The address path to the DIMM is available
- The data path to or from the DIMM is available
Note that we are not concerned about fixed offsets in time. The bank will not be used at the same moment as the address path, but since there is no queue in the DIMM or the DRAM it will be used at a constant number of cycles later, so it is treated as if it is used at the same time.
We are assuming "posted CAS"; that is, we send the READ or WRITE immediately after the ACTIVATE. This makes scheduling the address bus trivial; we always schedule a fixed set of cycles. For DDR-400, this is a set of two cycles; for some configurations such as DDR-800 the parameter tRRD forces this to be set to three cycles.
We assume a four-bit-time transfer on the data wires. This is the minimum burst length for DDR-2. This would correspond to (for example) a memory where each DIMM is 72 bits wide and DIMMs are ganged in pairs to deliver 64 bytes at a shot.This gives us the same occupancy on the data wires as on the address wires (for the two-address-cycle case).
The only non-trivial scheduling problem is the data wires. A write will use the wires earlier in the operation than a read will; typically one cycle earlier as seen at the DRAM, but earlier by a worst-case round-trip wire delay when seen at the memory controller. So, while reads from one rank can be scheduled back-to-back every two cycles, and writes (to any rank) scheduled every two cycles, when a read is followed by a write we need to insert a bubble. Furthermore, consecutive reads from two different ranks may need to insert a bubble due to skew between when one DRAM stops driving the wires and when the other one starts. (These bubbles are parameters.)
This means that when some number of reads and writes are at the heads of their queues, reads could starve writes, and/or reads to the same rank could starve out other requests, since the others would never see the data bus ready. For this reason, we have implemented an anti-starvation feature. A group of requests is marked "old", and a counter is incremented each cycle as long as any request from that batch has not issued. If the counter reaches twice the bank busy time, we hold off any newer requests until all of the "old" requests have issued.
Interconnection Network
Topology specification
Python files specify connections. Shortest path graph traversals program the routing tables.
Network implementation
- SimpleNetwork
- Garnet
Life of a memory request in Ruby
Cpu model generates a packet -> RubyPort converts it to a ruby request -> L1 cache controller converts it to a protocol specific message ...etc.
Arka will do it